Going Beyond Infoboxes to Extract Information from Wikipedia
Lector (Latin for reader) is a joint research project between the DB group of Roma Tre University and DB group of University of Alberta. The project aims to extract facts from the text in Wikipedia articles to complete Wikipedia-derived Knowledge Graphs (KGs) such as DBpedia and YAGO.
Wikipedia as a Gold-mine for Knowledge
Wikipedia remains one of the primary sources of knowledge on the Web, and for many good reasons. First, it is open. Second, it is edited by a large team of passionate and dedicated editors, who are truly committed to providing informative and accurate factual information. Finally, it is subject to strict and semi automated quality control processes that eliminate many forms of spam.
Not surprisingly, many approaches have been introduced recently to automatically create or augment KGs with facts extracted from Wikipedia, particularly from its structured components like the infoboxes. DBPedia pioneered the trend, providing up-to-date dumps of triples derived from the data in the Inforboxes. YAGO added a wealth of semantic information to the mix, by matching the noisy and incomplete system of categories in Wikipedia into a clean and useful type hierarchy borrowed from WordNet, bringing order to the picture.
Many good things came out of these efforts, with an emblematic example being the Watson system winning the Jeopardy question answering contest against humans.
Along Came Freebase
In a nutshell, Freebase was to data what Wikipedia is to text. Sadly, it is no longer maintained. It grew to be the largest open knowledge graph on the Web, built by a large community of developers and enthusiasts. Since anyone could (and a lot of people did) contribute to Freebase, it had a lot more entities and a lot more relationships than DBpedia and YAGO. One key reason for Freebase to exist was Wikipedia’s editorial policies, which require entities to reach some prominence before they can be added. This precludes Wikipedia having, for instance, all the latest movies from IMDB. Yet, anyone could add all such data to Freebase easily.
Lector Goes Beyond Infoboxes
The state of affairs at the time we did this work was thus as follows. Freebase was (and remains) frozen for updates, and the two major open knowledge graphs are derived from Wikipedia and are thus restricted to the facts expressed in their Infoboxes. Although infoboxes and the article category system in Wikipedia are invaluable, they represent only a fraction of the actual information expressed in Wikipedia itself. In fact, it is estimated that 65% of Wikipedia articles have no Infoboxes, which motivates research on how to extract facts from other sources besides the Infoboxes.
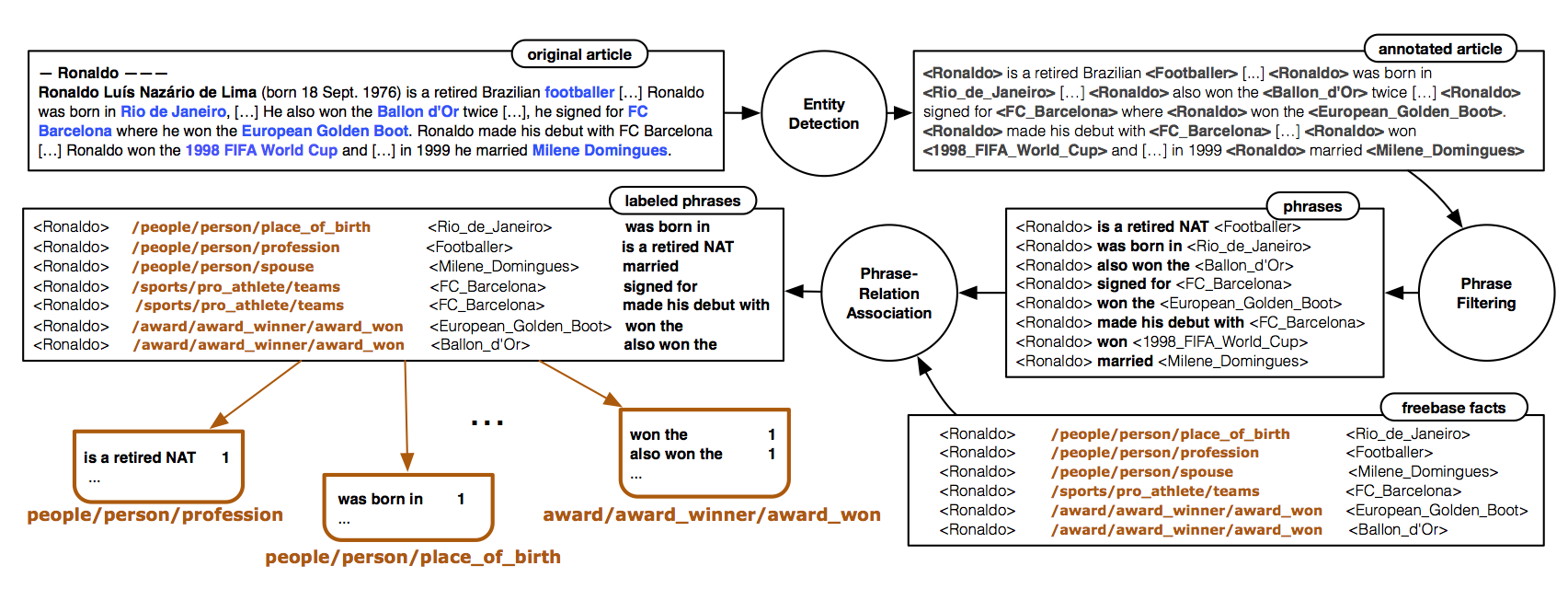
Our approach was to literally read the text in the Wikipedia articles looking for relational sentences connecting pairs of entities that are related in Freebase. We built language models for each Freebase relation by considering the phrases connecting pairs of entities that we knew were related. Then, for pairs of entities for which no relation was known, we used the corresponding phrases as queries over the language models we built. The image below shows the pipeline that bring us to create relations language models:
Results
We applied this idea to extract facts from Wikipedia articles and checked if they were present in DBPedia, YAGO and Freebase as well. More precisely, we can find hundreds of thousands of facts between entities that exist in Wikipedia and yet are missing in DBPedia, YAGO, and Freebase. In some cases, we can grow the relations in such KGs by as much as 10%, which is remarkable given the effort that went in building them.
To assess the accuracy of our Lector method, we followed the evaluation protocol for YAGO and considered random samples of the extractions. We found that we our accuracy is over 95%, which is competitive with the state of the art.